 v kategorii
v kategorii Už je to dlouho, co jsem se s vámi chtěl podělit o tip, jak vytvořit datový typ boolean v databázi MySQL trochu jinak. Nějak jsem na to úplně zapomněl, takže se s ním dělím dnes.
V MySQL datový typ boolean
je, ale není to samostatný datový typ, nýbrž alias pro
TINYINT(1). V normálních situacích by to mělo stačit, ale občas nastane
prostě specifická situace, kdy to nepostačuje…
Dělám totiž na business aplikaci, kde je velmi často co nějaký formulářový prvek, to atribut v databázi. Každý takový formulářový prvek je nějak omezen a uživatele musíme případně upozornit, pokud takové hranice překročí. Programátor je od přírody tvorem lenivým a proto nic nepíše dvakrát (tzv. DRY) a tudíž ani my jsme nechtěli validace psát vícekrát.
„Vícekrát?“ ptáte se? Ano, vícekrát. Nejenom, že musím někde v kódu
specifikovat validační pravidla, ale i databázi musím nějak nastavit. Už jenom
tohle je dvakrát a to nepočítám nějaké menší kontroly na straně klienta – v
JavaScriptu. Například věk. V databázi musím určit TINYINT a v kódu ošetřit
vstup, aby mi minimálně databáze neodpověděla out of range.
Abychom to nemuseli dělat, napsali jsme si takovou fičuru – při nastartování
aplikace se přečte celá databáze a pro každý atribut v každé tabulce se
sestaví validační pravidlo. Jaký to je datový typ a jaká jsou omezení
(maximum/minimum, maximální/minimální délka, možnost nastavit NULL, …). A
tato pravidla se využijí při validaci (která si samozřejmě můžeme v aplikaci
ještě zpřísnit).
Tedy když pomocí SQL syntaxe řeknu, že e-mail může být maximálně 256 znaků dlouhý, nemusím toto stejné číslo použít znovu někde v kódu. A kdyby se náhodou toto omezení změnilo, stačí provést úpravu na jednom místě.
Řešení to je hezké a funguje nám to bez problémů dlouho (něco přes rok), ale
měli jsme s tím při programování menší problém. Jednalo se o datový typ
boolean. V databázi jsme ho měli jako každý jiný vytvořen pomocí TINYINT(1),
jenže takto tam máme i atributy, které jsou skutečně celočíselné – nabývající
od nuly do devíti.
Člověk je rozliší poměrně jednoduše podle názvu, ale robot generující validační pravidla to má o něco horší. Mohli jsme mu to usnadnit například nějakým speciálním zápisem do poznámky, ale to není úplně to pravé ořechové. Poznámka / komentář je jen poznámka / komentář. Něco takového by nemělo být rozhodujícím pro běh programu. To jsme tedy neudělali.
Udělali jsme to, že TINYINT(1) jsme převedli (kde se jednalo o logickou
hodnotu) na BIT(1). Dřív byl BIT také alias pro TINYINT, ale od MySQL
5.0.3 je to samostatný datový typ, takže ho lze rozlišit a dokonce může
správně nabývat pouze dvou hodnot.
Výhody to nemá – datově si nijak nepolepšíme (BIT(1) zabírá totéž jako
BIT(2) nebo i BIT(8)) a nepolepšíme si ani nijak jinak. Vlastně si ještě
ztížíme práci, protože BIT se přenáší jako BINARY, což je v MySQL řetězec.
Na to je jednoduchá náprava: stačí hodnotu převádět například pomocí funkce
CONVERT.
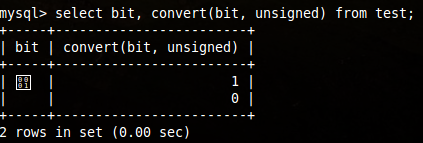
MySQL dokumentace radí i převádění pomocí přičtení nuly, ale to mi nepřijde zrovna přehledné. Ale je to kratší když pracujete v konzoli. ;)
Jinak žádné další problémy s použitím BITu jsme neměli. Dokonce je teď
jasnější, že se jedná o logickou hodnotu, protože TINYINT(1) prostě neříká
„hej, čau, já jsem nějaký flag!“ Což potvrzuje to, že máme skutečně atributy
TINYINT(1), které nejsou logické.
Pokud tedy někdy přestane vyhovovat TINYINT(1) jako logická hodnota i vám a
v MySQL stále nebude (stále není v poslední MySQL 5.6) pravý BOOLEAN, zkuste
náhradní řešení s BIT(1).
Pro vysoký výkon se hodí naopak něco jiného: CHAR(0) DEFAULT NULL (v případe
InnoDB). Tohle řešení se mi mi zdá velmi ugly, ale co bychom neudělali pro
vysoký výkon, že? :) O tom už ale jinde, například v knize High Performance
MySQL
nebo v článku Efficient Boolean value storage for Innodb Tables.
